
철솜_STUDY
파이썬 머신러닝 완벽 가이드 _CH.5 본문
CH.5.1 _ 회귀 소개
회귀는 현대 통계학의 주요 기둥이다.
사람의 키는 평균 키로 회귀하려는 경향을 가진다는 자연의 법칙을 밝혀낸 영국의 통계학자 갈톤이 수행한 연구에서 유래했다. 회귀 분석은 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법이다.
회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 의미한다.
식을 쓰면 Y = W1*X1 + W2*X2 + W3*X3 +... 와 같다
여기서 Y는 종속변수, X는 독립변수, W는 독립변수의 값에 영향을 미치는 회귀계수이다.
머신러닝 관점에서 보면 X는 피처, Y는 결정 값이다.
회귀분석의 핵심은 주어진 피처와 결정 값 데이터에 기반으로 학습을 통해 최적의 회귀 계수를 찾아내는 것이다.
회귀는 회귀 계수의 선형/비선형 여부, 독립변수의 개수, 종속변수의 개수에 따라 여러 유형으로 나뉜다.
독립변수 개수 1개 = 단일 회귀 // 여러개 = 다중 회귀
회귀 계수의 결합이 선형 = 선형 회귀 // 비선형 결합 = 비선형 회귀
지도 학습은 두 가지 유형으로 나뉘는데 분류와 회귀이다.
가장 큰 차이는 예측값의 유형이 이산형(분류)인지, 연속형(회귀)인지이다.
선형회귀는 실제 값과 예측값의 차이 (오류의 제곱 값)을 최소화하는 직선형 회귀선을 최적화하는 방식이다.
선형 회귀 모델은 Regularization 방법*에 따라 종류가 나뉘는데
1. 일반 선형 회귀 2. 릿지 3. 라쏘 4. 엘라스틱넷 5. 로지스틱 회귀 이다.
*규제 : 과적합 문제를 해결하기 위해 회귀 계수에 패널티 값을 적용하는 것
CH.5.2 _ 단순 선형 회귀를 통한 회귀 이해
단순 선형 회귀는 독립변수와 종속변수 모두 하나인 선형 회귀이다.

Y = w0 + w1*x1
예측값 ^Y = w0+w1*X
*w0= intercept(절편) / w1 = 기울기 >> 이 둘이 회귀 계수이다.
실제 값 Y=w0+w1*X + e(잔차)
>> 실제값-예측값 = e(잔차) >> 이 잔차의 합이 최소가 되는 모델을 만드는 것이 최적의 회귀 모델을 만든다는 의미이다.
>> 잔차는 음수, 양수가 모두 되기 때문에 단순히 더하는 방식으로는 완벽한 반영이 불가능하다.
이 때 취하는 방식에 따라 종류가 나뉘게 된다.
일반적으로는 RSS 방식*을 사용하지만, 오류의 절댓값 합을 더하는 방식이 있기도 하다.
*RSS = 오류 값의 제곱을 구해 더하는 방식 = Residual Sum of Square
**error^2 = Residual = RSS
RSS 는 변수가 w0, w1인 식으로 표현된다. 그러므로 기존의 독립변수, 종속변수 X,Y는 더이상 중심 변수가 아니다.

회귀에서 RSS는 비용_Cost이며, w변수_회귀계수로 구성되는 RSS는 비용 함수=손실함수라고 불린다.
머신러닝 회귀 알고리즘은 데이터를 학습하며 비용함수의 반환값 = 오류값을 지속해서 감소시키고, 더이상 감소하지 않는 최소의 오류 값을 구하는 것이다.
CH.5.3 _ 비용 최소화 하기 _ 경사하강법* 소개
*경사 하강법 = Gradient Descent
비용함수가 최소가 되는 w 파라미터를 구하는 방법이 경사 하강법이다.
- 경사 하강법 : 점진적으로 반복적인 계산을 통해 W 파라미터 값을 업데이터 하면서 오류 값이 최소가 되는 W 파라미터를 구하는 방식
- 반복적으로 비용 함수의 반환 값, 즉 예측값과 실제 값의차 이가 작아지는 방향성을 가지고 W 파라미터를 지속적으로 보정해나감 → 오류 값이 더 이상 작아지지 않으면 그 오류 값을 최소 비용으로 판단하고 그때의 W 값을 최적의 파라미터로 반환
경사하강법 과정
- 최초 w에서 미분을 적용해 미분 값이 계속 감소하는 방향으로 순차적으로 w를 업데이트
- 1차 함수의 기울기가 감소하지 않는 지점을 비용 함수가 최소인 지점으로 간주하고 그 때의 w를 반환

요약
Step 1 : 임의의 값으로 첫 비용함수의 값 계산
Step 2 : 편미분 결과값에 학습률(보정계수)를 곱한 것을 마이너스하면서 계산하여 이전 값 업데이트
Step 3: 비용함수 값이 최소가 될 때 반복을 중지, 최적 파라미터 구함
경사 하강법의 단점 : 모든 학습 데이터에 대해 반복적으로 비용함수 최소화를 위한 값을 업데이트 하기 때문에, 수행 시간이 매우 오래 걸림.
→ 확률적 경사 하강법 (Stochastic Gradient Descent) 사용
: 전체 입력 데이터로 업데이트하는 것이 아닌, 일부 데이터만 이용해 w가 업데이트되는 값을 계산 → 경사하강법보다 빠른 속도 보장
⇒ 대용량의 데이터를 처리할 때에는 주로 확률적 경사 하강법 이용
피처가 여러 개인 경우 회귀 계수 도출

CH.5.4 _ LinearRegression을 이용한 보스턴 주택 가격 예측
LinearRegression 클래스 - Ordinary Least Squares
- LinearRegression 클래스 : 예측값과 실제 값의 RSS를 최소화해 OLS 추정 방식으로 구현한 클래스
- 입력 파라미터
- fit_intercept : 불린 값, 절편을 계산할 지 말지 결정
- normalize : 불린 값, 회귀 수행 전, 데이터 세트를 정규화 할지
- 속성
- coef : fit() 메서드를 수행했을 때 회귀 계수가 배열 형태로 저장하는 속성. Shape는 (Target 값 개수, 피처 개수)
- intercept_ : 절편 값
- 입력 파라미터
- 다중 공산성
- 피처 간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 민감해지는 현상
- 독립적이고 중요한 피처만 남기고 제거하거나 규제를 적용하면 됨 + PCA(주성분분석)을 통해 차원 축소도 고려
- 피처 간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 민감해지는 현상
회귀 평가 지표
- 평가 지표
- MAE : 평균 절대 오차, 실제 값과 예측 값의 차이를 절댓갑승로 변화내 평균한 것
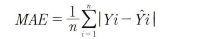
- MSE : 평균 제곱 오차, 실제 값과 예측값의 차이를 제곱해 평균한 것

- RMSE : MSE값에 루트를 씌운 값

- : 실제 값의 분산 대비 예측값의 분산 비율, 1에 가까울 수록 예측 정확도가 높음

- crossval_score, GridSearchCV 같은 Scoring 함수에 회귀 평가 지표를 적용 할 때, neg라는 접두어가 붙는데, 음수값을 가짐.
- 평가 지표 값에 -1을 곱해서 보정해주는 것이 필요
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.datasets import load_boston
%matplotlib inline
boston = load_boston()
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
bostonDF['PRICE'] = boston.target
print('Boston 데이타셋 크기 :',bostonDF.shape)
bostonDF.head()
fig, axs = plt.subplots(figsize=(16,8) , ncols=4 , nrows=2)
lm_features = ['RM','ZN','INDUS','NOX','AGE','PTRATIO','LSTAT','RAD']
for i , feature in enumerate(lm_features):
row = int(i/4)
col = i%4
sns.regplot(x=feature , y='PRICE',data=bostonDF , ax=axs[row][col])
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error , r2_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
X_train , X_test , y_train , y_test = train_test_split(X_data , y_target ,test_size=0.3, random_state=156)
lr = LinearRegression()
lr.fit(X_train ,y_train )
y_preds = lr.predict(X_test)
mse = mean_squared_error(y_test, y_preds)
rmse = np.sqrt(mse)
print('MSE : {0:.3f} , RMSE : {1:.3F}'.format(mse , rmse))
print('Variance score : {0:.3f}'.format(r2_score(y_test, y_preds)))
coeff = pd.Series(data=np.round(lr.coef_, 1), index=X_data.columns )
coeff.sort_values(ascending=False)
from sklearn.model_selection import cross_val_score
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
lr = LinearRegression()
neg_mse_scores = cross_val_score(lr, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores, 2))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
CH.5.5 _ 다항 회귀와 과적합/과소적합 이해
다항 회귀 이해
- 다항 회귀 : 회귀가 독립변수의 단항식이 아닌, 2차, 3차 방정식과 같은 다항식으로 표현되는 것
- 다항 회귀 역시 선형 회귀임.
- 사이킷 런의 PolynomialFeatures 클래스를 통해서 다항식 피처로 변환
- fit(), transform() 메서드를 통해 변환 작업 수행
다항 회귀를 이용한 과소적합 및 과적합 이해
- 다항 회귀는 복잡한 다항 관계를 모델링할 수 있음. 단, 차수를 높일수록 학습 데이터에만 너무 맞춘 학습이 이루어져 정작 테스트 데이터 환경에서는 오히려 예측 정확도가 떨어짐 → 과적합 문제 발생

- Degree 1 : 단순 선형 회귀, 예측 곡선이 학습 데이터의 패턴을 제대로 반영하지 못하고 있는 과소 적합 모델
- Degree 4 : 실제 데이터 세트와 유사한 모습, 학습 데이터 세트를 비교적 잘 반영해 코사인 곡선 기반으로 테스트 데이터를 잘 예측한 곡선을 가진 모델이 됨.
- Degree 15 : 데이터 세트의 변동 잡음까지 모두 반영한 결과, 학습 데이터에만 적합하고, 테스트 갑스이 실제 곡선과는 완전히 다른 과적합 형태의 곡선이 발생
편향-분산 트레이드오프
Degree 1 : 고편향성 → 단순화된 모델, 지나치게 한 방향으로 치우침
Degree 15 : 고분산성 → 복잡한 모델, 지나치게 높은 변동성

- 저편향/저분산 : 예측 결과가 실제 결과에 매우 근접, 변동이 크지도 않고 뛰어난 성능
- 저편향/고분산 : 예측 결과가 실제 결과에 비교적 근접하지만, 예측 결과가 실제 결과를 중심으로 꽤 넓은 부분에 분포 (과대적합)
- 고편향/저분산 : 정확한 결과에서 벗어나면서도 예측이 특정 부분에 집중 (과소적합)
- 고편향/고분산 : 정확한 예측 결과를 벗어나면서도 넓은 부분에 분포
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
X = np.arange(4).reshape(2,2)
print('일차 단항식 계수 feature:\n',X )
poly = PolynomialFeatures(degree=2)
poly.fit(X)
poly_ftr = poly.transform(X)
print('변환된 2차 다항식 계수 feature:\n', poly_ftr)
def polynomial_func(X):
y = 1 + 2*X[:,0] + 3*X[:,0]**2 + 4*X[:,1]**3
print(X[:, 0])
print(X[:, 1])
return y
X = np.arange(0,4).reshape(2,2)
print('일차 단항식 계수 feature: \n' ,X)
y = polynomial_func(X)
print('삼차 다항식 결정값: \n', y)
poly_ftr = PolynomialFeatures(degree=3).fit_transform(X)
print('3차 다항식 계수 feature: \n',poly_ftr)
model = LinearRegression()
model.fit(poly_ftr,y)
print('Polynomial 회귀 계수\n' , np.round(model.coef_, 2))
print('Polynomial 회귀 Shape :', model.coef_.shape)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
def polynomial_func(X):
y = 1 + 2*X[:,0] + 3*X[:,0]**2 + 4*X[:,1]**3
return y
model = Pipeline([('poly', PolynomialFeatures(degree=3)),
('linear', LinearRegression())])
X = np.arange(4).reshape(2,2)
y = polynomial_func(X)
model = model.fit(X, y)
print('Polynomial 회귀 계수\n', np.round(model.named_steps['linear'].coef_, 2))
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
%matplotlib inline
def true_fun(X):
return np.cos(1.5 * np.pi * X)
np.random.seed(0)
n_samples = 30
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
plt.figure(figsize=(14, 5))
degrees = [1, 4, 15]
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features = PolynomialFeatures(degree=degrees[i], include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
pipeline.fit(X.reshape(-1, 1), y)
scores = cross_val_score(pipeline, X.reshape(-1,1), y,scoring="neg_mean_squared_error", cv=10)
coefficients = pipeline.named_steps['linear_regression'].coef_
print('\nDegree {0} 회귀 계수는 {1} 입니다.'.format(degrees[i], np.round(coefficients),2))
print('Degree {0} MSE 는 {1:.2f} 입니다.'.format(degrees[i] , -1*np.mean(scores)))
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), '--', label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x"); plt.ylabel("y"); plt.xlim((0, 1)); plt.ylim((-2, 2)); plt.legend(loc="best")
plt.title("Degree {}\nMSE = {:.2e}(+/- {:.2e})".format(degrees[i], -scores.mean(), scores.std()))
plt.show()
CH.5.6 _ 규제 선형 모델 - 릿지, 라쏘, 엘라스틱넷
규제 선형 모델 개요
- 규제의 필요성 : 회귀 모델은 적절히 데이터에 적합하면서도 회귀 계수가 기하급수적으로 커지는 것을 제어할 수 있어야 함.
-
- 비용 함수는 학습 데이터의 잔차 오류 값을 최소로 하는 RSS 최소화 방법과 과적합을 방지하기 위해 회귀 계수 값이 커지지 않도록 하는 방법이 서로 균형을 이루어야 함.

- 비용 함수 목표 =
- alpha : 학습 데이터 적합 정도와 회귀 계수 값의 크기 제어를 수행하는 튜닝 파라미터
- alpha값이 크면, 비용 함수는 회귀 계수의 w값을 작게 해 과적합을 개선할 수 있으며, alpha 값을 작게 하면, 회귀 계수 w의 값을 작게 해 과적합을 개선할 수 있으며, alpha 값을 작게 하면 회귀 계수의 w 값이 커져도 어느 정도 상쇄가 가능하므로 학습 데이터 적합을 더 개선할 수 있음. 
-
- 규제 : 비용 함수에 alpha 값으로 패널티를 부여해 회귀 계수 값의 크기를 감소시켜 과적합을 개선하는 방식
릿지 회귀
- Ridge : 선형 회귀에 L2 규제를 추가한 회귀 모델, 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해 회귀 계수 값을 더 작게 만드는 방식
- 회귀 계수를 0으로 만들고 있지는 않지만, alpha가 커질수록 회귀 계수가 지속적으로 작아지는 것을 확인할 수 있음 → 회귀 계수를 0으로 만들지는 않음

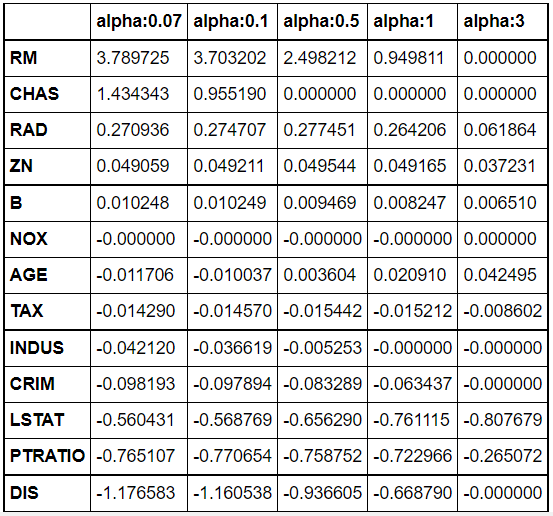
라쏘 회귀
- 라쏘 : L1 규제 추가한 회귀 모델, 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어 회귀 예측시 피처가 선택되지 않도록 하는 것
- 불필요한 회귀 계수를 급격하게 감소시켜 0으로 만드는 것
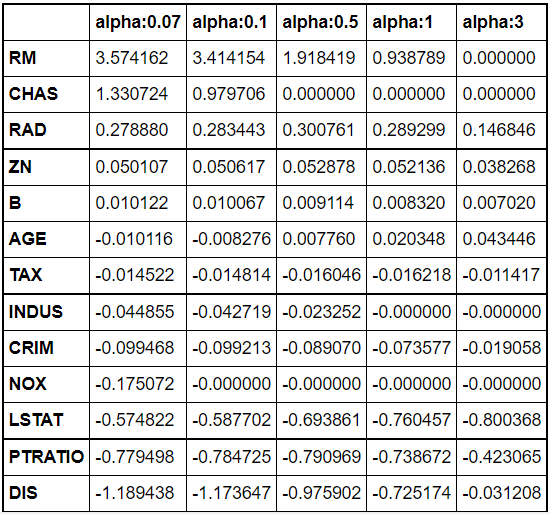
엘라스틱넷 회귀
- 엘라스틱넷 : L1 + L2를 결합, L1 규제로 피처의 개수를 줄임과 동시에, L2로 계수 값의 크기 조정
- 라쏘 회귀가 서로 상관관계가 높은 피처들 중 중요 피처만을 선택하고, 다른 피처들의 회귀 계수를 0으로 만드는 성향을 가져, alpha값에 따라 회귀 계수 값이 급격히 변동할 수 있다는 단점 완화하기 위함.
- alpha: (a+b)값. a: L1 규제 alpha값 / b: L2 규제 alpha 값
- l1_ratio = a/(a+b)
선형 회귀 모델을 위한 데이터 변환
- 선형 회귀 모델은 피처값과 타깃값의 분포가 정규 분포 형태를 매우 선호
- 특히 타깃값이 한쪽으로 치우친 왜곡된 형태의 분포도일 때 예측 성능에 부정적인 영향을 미칠 가능성이 높음.
- 선형 회귀 모델을 적용하기 전, 데이터에 대한 스케일링 / 정규화를 진행하는 것이 일반적
- StandardScaler() 표준화, MinMaxScaler 정규화 → 성능 향상을 기대하기 어려움
- 스케일링/정규화를 수행한 데이터 세트에 다시 다항 특성을 적용하여 반환 → 과적합 이슈 발생 가능
- log 변환: 가장 많이 사용되는 방법
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
ridge = Ridge(alpha = 10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 3))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores,3))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
alphas = [0 , 0.1 , 1 , 10 , 100]
for alpha in alphas :
ridge = Ridge(alpha = alpha)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0} 일 때 5 folds 의 평균 RMSE : {1:.3f} '.format(alpha,avg_rmse))
fig , axs = plt.subplots(figsize=(18,6) , nrows=1 , ncols=5)
coeff_df = pd.DataFrame()
for pos , alpha in enumerate(alphas) :
ridge = Ridge(alpha = alpha)
ridge.fit(X_data , y_target)
coeff = pd.Series(data=ridge.coef_ , index=X_data.columns )
colname='alpha:'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values , y=coeff.index, ax=axs[pos])
plt.show()
ridge_alphas = [0 , 0.1 , 1 , 10 , 100]
sort_column = 'alpha:'+str(ridge_alphas[0])
coeff_df.sort_values(by=sort_column, ascending=False)
#라쏘 회귀
from sklearn.linear_model import Lasso, ElasticNet
def get_linear_reg_eval(model_name, params=None, X_data_n=None, y_target_n=None, verbose=True):
coeff_df = pd.DataFrame()
if verbose : print('####### ', model_name , '#######')
for param in params:
if model_name =='Ridge': model = Ridge(alpha=param)
elif model_name =='Lasso': model = Lasso(alpha=param)
elif model_name =='ElasticNet': model = ElasticNet(alpha=param, l1_ratio=0.7)
neg_mse_scores = cross_val_score(model, X_data_n,
y_target_n, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0}일 때 5 폴드 세트의 평균 RMSE: {1:.3f} '.format(param, avg_rmse))
model.fit(X_data , y_target)
coeff = pd.Series(data=model.coef_ , index=X_data.columns )
colname='alpha:'+str(param)
coeff_df[colname] = coeff
return coeff_df
lasso_alphas = [ 0.07, 0.1, 0.5, 1, 3]
coeff_lasso_df =get_linear_reg_eval('Lasso', params=lasso_alphas, X_data_n=X_data, y_target_n=y_target)
sort_column = 'alpha:'+str(lasso_alphas[0])
coeff_lasso_df.sort_values(by=sort_column, ascending=False)
#엘라스틱넷 회귀
elastic_alphas = [ 0.07, 0.1, 0.5, 1, 3]
coeff_elastic_df =get_linear_reg_eval('ElasticNet', params=elastic_alphas,
X_data_n=X_data, y_target_n=y_target)
sort_column = 'alpha:'+str(elastic_alphas[0])
coeff_elastic_df.sort_values(by=sort_column, ascending=False)
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
def get_scaled_data(method='None', p_degree=None, input_data=None):
if method == 'Standard':
scaled_data = StandardScaler().fit_transform(input_data)
elif method == 'MinMax':
scaled_data = MinMaxScaler().fit_transform(input_data)
elif method == 'Log':
scaled_data = np.log1p(input_data)
else:
scaled_data = input_data
if p_degree != None:
scaled_data = PolynomialFeatures(degree=p_degree,
include_bias=False).fit_transform(scaled_data)
return scaled_data
alphas = [0.1, 1, 10, 100]
scale_methods=[(None, None), ('Standard', None), ('Standard', 2),
('MinMax', None), ('MinMax', 2), ('Log', None)]
for scale_method in scale_methods:
X_data_scaled = get_scaled_data(method=scale_method[0], p_degree=scale_method[1],
input_data=X_data)
print('\n## 변환 유형:{0}, Polynomial Degree:{1}'.format(scale_method[0], scale_method[1]))
get_linear_reg_eval('Ridge', params=alphas, X_data_n=X_data_scaled,
y_target_n=y_target, verbose=False)CH.5.7 _ 로지스틱 회귀
- 로지스틱 회귀 : 선형 회귀 방식을 분류에 적용한 알고리즘
- 시그모이드 함수 최적선을 찾고 이 시그모이드 함수의 반환 값을 확률로 간주해 확률에 따라 분류 결정

- x값이 아무리 커지거나 작아져도 y값은 0과 1사이 값 반환

import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
cancer = load_breast_cancer()
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
scaler = StandardScaler()
data_scaled = scaler.fit_transform(cancer.data)
X_train , X_test, y_train , y_test = train_test_split(data_scaled, cancer.target, test_size=0.3, random_state=0)
from sklearn.metrics import accuracy_score, roc_auc_score
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
lr_preds = lr_clf.predict(X_test)
print('accuracy: {:0.3f}'.format(accuracy_score(y_test, lr_preds)))
print('roc_auc: {:0.3f}'.format(roc_auc_score(y_test , lr_preds)))
solvers=['lbfgs', 'liblinear', 'newton-cg', 'sag', 'saga']
for solver in solvers:
lr_clf=LogisticRegression(solver=solver, max_iter=600)
lr_clf.fit(X_train, y_train)
lr_preds=lr_clf.predict(X_test)
lr_preds_proba=lr_clf.predict_proba(X_test)[:,-1]
print('solver:{0}, accuracy:{1:.3f}, roc_auc:{2:.3f}'.format(solver, accuracy_score(y_test, lr_preds), roc_auc_score(y_test, lr_preds_proba)))
from sklearn.model_selection import GridSearchCV
params={'penalty':['l2', 'l1'],
'C':[0.01, 0.1, 1, 1, 5, 10]}
grid_clf = GridSearchCV(lr_clf, param_grid=params, scoring='accuracy', cv=3 )
grid_clf.fit(data_scaled, cancer.target)
print('최적 하이퍼 파라미터:{0}, 최적 평균 정확도:{1:.3f}'.format(grid_clf.best_params_,
grid_clf.best_score_))
CH.5.8 _ 회귀트리
- 트리 기반의 회귀 : 회귀 트리 이용 → 회귀를 위한 트리를 생성하고 이를 기반으로 회귀 예측을 하는 것
↔ 분류 트리와의 차이점 : 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산

- 결정 트리, 랜덤 포레스트, GBM, XGBoost, LightGBM 등 모든 트리 기반 알고리즘은 회귀도 가능 → 트리 생성이 CART 알고리즘에 기반하기 때문
- 회귀 트리는 선형 회귀와 다르게 분할되는 데이터 지점에 따라 브랜치를 만들면서 계단 형태로 회귀선을 만듦.
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
boston = load_boston()
bostonDF = pd.DataFrame(boston.data, columns = boston.feature_names)
bostonDF['PRICE'] = boston.target
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'], axis=1,inplace=False)
rf = RandomForestRegressor(random_state=0, n_estimators=1000)
neg_mse_scores = cross_val_score(rf, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 교차 검증의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 2))
print(' 5 교차 검증의 개별 RMSE scores : ', np.round(rmse_scores, 2))
print(' 5 교차 검증의 평균 RMSE : {0:.3f} '.format(avg_rmse))
def get_model_cv_prediction(model, X_data, y_target):
neg_mse_scores = cross_val_score(model, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print('##### ',model.__class__.__name__ , ' #####')
print(' 5 교차 검증의 평균 RMSE : {0:.3f} '.format(avg_rmse))
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=4)
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
gb_reg = GradientBoostingRegressor(random_state=0, n_estimators=1000)
xgb_reg = XGBRegressor(n_estimators=1000)
lgb_reg = LGBMRegressor(n_estimators=1000)
models = [dt_reg, rf_reg, gb_reg, xgb_reg, lgb_reg]
for model in models:
get_model_cv_prediction(model, X_data, y_target)
import seaborn as sns
%matplotlib inline
rf_reg = RandomForestRegressor(n_estimators=1000)
rf_reg.fit(X_data, y_target)
feature_series = pd.Series(data=rf_reg.feature_importances_, index=X_data.columns )
feature_series = feature_series.sort_values(ascending=False)
sns.barplot(x= feature_series, y=feature_series.index)
import matplotlib.pyplot as plt
%matplotlib inline
bostonDF_sample = bostonDF[['RM','PRICE']]
bostonDF_sample = bostonDF_sample.sample(n=100,random_state=0)
print(bostonDF_sample.shape)
plt.figure()
plt.scatter(bostonDF_sample.RM , bostonDF_sample.PRICE,c="darkorange")
import numpy as np
from sklearn.linear_model import LinearRegression
lr_reg = LinearRegression()
rf_reg2 = DecisionTreeRegressor(max_depth=2)
rf_reg7 = DecisionTreeRegressor(max_depth=7)
X_test = np.arange(4.5, 8.5, 0.04).reshape(-1, 1)
X_feature = bostonDF_sample['RM'].values.reshape(-1,1)
y_target = bostonDF_sample['PRICE'].values.reshape(-1,1)
lr_reg.fit(X_feature, y_target)
rf_reg2.fit(X_feature, y_target)
rf_reg7.fit(X_feature, y_target)
pred_lr = lr_reg.predict(X_test)
pred_rf2 = rf_reg2.predict(X_test)
pred_rf7 = rf_reg7.predict(X_test)
fig , (ax1, ax2, ax3) = plt.subplots(figsize=(14,4), ncols=3)
ax1.set_title('Linear Regression')
ax1.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax1.plot(X_test, pred_lr,label="linear", linewidth=2 )
ax2.set_title('Decision Tree Regression: \n max_depth=2')
ax2.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax2.plot(X_test, pred_rf2, label="max_depth:3", linewidth=2 )
ax3.set_title('Decision Tree Regression: \n max_depth=7')
ax3.scatter(bostonDF_sample.RM, bostonDF_sample.PRICE, c="darkorange")
ax3.plot(X_test, pred_rf7, label="max_depth:7", linewidth=2)CH.5.9 _ 회귀 실습1
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore", category=RuntimeWarning)
bike_df = pd.read_csv('./bike_train.csv')
print(bike_df.shape)
bike_df.head(3)
bike_df.info()
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x: x.hour)
bike_df.head(3)
drop_columns = ['datetime','casual','registered']
bike_df.drop(drop_columns, axis=1,inplace=True)
fig, axs=plt.subplots(figsize=(16, 8), ncols=4, nrows=2)
cat_features=['year', 'month', 'season', 'weather', 'day', 'hour', 'holiday', 'workingday']
for i, feature in enumerate(cat_features):
row=int(i/4)
col=i%4
sns.barplot(x=feature, y='count', data=bike_df, ax=axs[row][col])
from sklearn.metrics import mean_squared_error, mean_absolute_error
def rmsle(y, pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred) ** 2
rmsle = np.sqrt(np.mean(squared_error))
return rmsle
def rmse(y,pred):
return np.sqrt(mean_squared_error(y,pred))
def evaluate_regr(y,pred):
rmsle_val = rmsle(y,pred)
rmse_val = rmse(y,pred)
mae_val = mean_absolute_error(y,pred)
print('RMSLE: {0:.3f}, RMSE: {1:.3F}, MAE: {2:.3F}'.format(rmsle_val, rmse_val, mae_val))
from sklearn.model_selection import train_test_split , GridSearchCV
from sklearn.linear_model import LinearRegression , Ridge , Lasso
y_target = bike_df['count']
X_features = bike_df.drop(['count'],axis=1,inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test ,pred)
def get_top_error_data(y_test, pred, n_tops = 5):
result_df = pd.DataFrame(y_test.values, columns=['real_count'])
result_df['predicted_count']= np.round(pred)
result_df['diff'] = np.abs(result_df['real_count'] - result_df['predicted_count'])
print(result_df.sort_values('diff', ascending=False)[:n_tops])
get_top_error_data(y_test,pred,n_tops=5)
y_target.hist()
y_log_transform = np.log1p(y_target)
y_log_transform.hist()
y_target_log = np.log1p(y_target)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target_log, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
y_test_exp = np.expm1(y_test)
pred_exp = np.expm1(pred)
evaluate_regr(y_test_exp ,pred_exp)
coef = pd.Series(lr_reg.coef_, index=X_features.columns)
coef_sort = coef.sort_values(ascending=False)
sns.barplot(x=coef_sort.values, y=coef_sort.index)
X_features_ohe = pd.get_dummies(X_features, columns=['year', 'month','day', 'hour', 'holiday',
'workingday','season','weather'])
X_train, X_test, y_train, y_test = train_test_split(X_features_ohe, y_target_log,
test_size=0.3, random_state=0)
def get_model_predict(model, X_train, X_test, y_train, y_test, is_expm1=False):
model.fit(X_train, y_train)
pred = model.predict(X_test)
if is_expm1 :
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print('###',model.__class__.__name__,'###')
evaluate_regr(y_test, pred)
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model,X_train, X_test, y_train, y_test,is_expm1=True)
coef = pd.Series(lr_reg.coef_ , index=X_features_ohe.columns)
coef_sort = coef.sort_values(ascending=False)[:20]
sns.barplot(x=coef_sort.values , y=coef_sort.index)
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
rf_reg = RandomForestRegressor(n_estimators=500)
gbm_reg = GradientBoostingRegressor(n_estimators=500)
xgb_reg = XGBRegressor(n_estimators=500)
lgbm_reg = LGBMRegressor(n_estimators=500)
for model in [rf_reg, gbm_reg, xgb_reg, lgbm_reg]:
get_model_predict(model,X_train.values, X_test.values, y_train.values, y_test.values,is_expm1=True)CH.5.10 _ 회귀 실습2
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
house_df_org = pd.read_csv('house_price.csv')
house_df = house_df_org.copy()
house_df.head(3)
plt.title('Original Sale Price Histogram')
sns.distplot(house_df['SalePrice'])
plt.title('Log Transformed Sale Price Histogram')
log_SalePrice = np.log1p(house_df['SalePrice'])
sns.distplot(log_SalePrice)
original_SalePrice = house_df['SalePrice']
house_df['SalePrice'] = np.log1p(house_df['SalePrice'])
house_df.drop(['Id','PoolQC' , 'MiscFeature', 'Alley', 'Fence','FireplaceQu'], axis=1 , inplace=True)
house_df.fillna(house_df.mean(),inplace=True)
null_column_count = house_df.isnull().sum()[house_df.isnull().sum() > 0]
print('## Null 피처의 Type :\n', house_df.dtypes[null_column_count.index])
house_df_ohe = pd.get_dummies(house_df)
null_column_count = house_df_ohe.isnull().sum()[house_df_ohe.isnull().sum() > 0]
def get_rmse(model):
pred = model.predict(X_test)
mse = mean_squared_error(y_test , pred)
rmse = np.sqrt(mse)
print('{0} 로그 변환된 RMSE: {1}'.format(model.__class__.__name__,np.round(rmse, 3)))
return rmse
def get_rmses(models):
rmses = [ ]
for model in models:
rmse = get_rmse(model)
rmses.append(rmse)
return rmses
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice',axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2, random_state=156)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge()
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso()
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
def get_top_bottom_coef(model):
coef = pd.Series(model.coef_, index=X_features.columns)
coef_high = coef.sort_values(ascending=False).head(10)
coef_low = coef.sort_values(ascending=False).tail(10)
return coef_high, coef_low
def visualize_coefficient(models):
fig, axs = plt.subplots(figsize=(24,10),nrows=1, ncols=3)
fig.tight_layout()
for i_num, model in enumerate(models):
coef_high, coef_low = get_top_bottom_coef(model)
coef_concat = pd.concat( [coef_high , coef_low] )
axs[i_num].set_title(model.__class__.__name__+' Coeffiecents', size=25)
axs[i_num].tick_params(axis="y",direction="in", pad=-120)
for label in (axs[i_num].get_xticklabels() + axs[i_num].get_yticklabels()):
label.set_fontsize(22)
sns.barplot(x=coef_concat.values, y=coef_concat.index , ax=axs[i_num])
models = [lr_reg, ridge_reg, lasso_reg]
visualize_coefficient(models)
from sklearn.model_selection import cross_val_score
def get_avg_rmse_cv(models):
for model in models:
rmse_list = np.sqrt(-cross_val_score(model, X_features, y_target,
scoring="neg_mean_squared_error", cv = 5))
rmse_avg = np.mean(rmse_list)
print('\n{0} CV RMSE 값 리스트: {1}'.format( model.__class__.__name__, np.round(rmse_list, 3)))
print('{0} CV 평균 RMSE 값: {1}'.format( model.__class__.__name__, np.round(rmse_avg, 3)))
models = [lr_reg, ridge_reg, lasso_reg]
get_avg_rmse_cv(models)
from sklearn.model_selection import GridSearchCV
def print_best_params(model, params):
grid_model = GridSearchCV(model, param_grid=params,
scoring='neg_mean_squared_error', cv=5)
grid_model.fit(X_features, y_target)
rmse = np.sqrt(-1* grid_model.best_score_)
print('{0} 5 CV 시 최적 평균 RMSE 값: {1}, 최적 alpha:{2}'.format(model.__class__.__name__,
np.round(rmse, 4), grid_model.best_params_))
return grid_model.best_estimator_
ridge_params = { 'alpha':[0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha':[0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1,5, 10] }
best_rige = print_best_params(ridge_reg, ridge_params)
best_lasso = print_best_params(lasso_reg, lasso_params)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
ridge_reg = Ridge(alpha=12)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
models = [lr_reg, ridge_reg, lasso_reg]
get_rmses(models)
models = [lr_reg, ridge_reg, lasso_reg]
visualize_coefficient(models)
from scipy.stats import skew
features_index = house_df.dtypes[house_df.dtypes != 'object'].index
skew_features = house_df[features_index].apply(lambda x : skew(x))
skew_features_top = skew_features[skew_features > 1]
print(skew_features_top.sort_values(ascending=False))
house_df[skew_features_top.index] = np.log1p(house_df[skew_features_top.index])
house_df_ohe = pd.get_dummies(house_df)
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice',axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2, random_state=156)
ridge_params = { 'alpha':[0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha':[0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1,5, 10] }
best_ridge = print_best_params(ridge_reg, ridge_params)
best_lasso = print_best_params(lasso_reg, lasso_params)
plt.scatter(x = house_df_org['GrLivArea'], y = house_df_org['SalePrice'])
plt.ylabel('SalePrice', fontsize=15)
plt.xlabel('GrLivArea', fontsize=15)
plt.show()
cond1 = house_df_ohe['GrLivArea'] > np.log1p(4000)
cond2 = house_df_ohe['SalePrice'] < np.log1p(500000)
outlier_index = house_df_ohe[cond1 & cond2].index
print('아웃라이어 레코드 index :', outlier_index.values)
print('아웃라이어 삭제 전 house_df_ohe shape:', house_df_ohe.shape)
house_df_ohe.drop(outlier_index , axis=0, inplace=True)
print('아웃라이어 삭제 후 house_df_ohe shape:', house_df_ohe.shape)
y_target = house_df_ohe['SalePrice']
X_features = house_df_ohe.drop('SalePrice',axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.2, random_state=156)
ridge_params = { 'alpha':[0.05, 0.1, 1, 5, 8, 10, 12, 15, 20] }
lasso_params = { 'alpha':[0.001, 0.005, 0.008, 0.05, 0.03, 0.1, 0.5, 1,5, 10] }
best_ridge = print_best_params(ridge_reg, ridge_params)
best_lasso = print_best_params(lasso_reg, lasso_params)from xgboost import XGBRegressor
xgb_params = {'n_estimators':[1000]}
xgb_reg = XGBRegressor(n_estimators=1000, learning_rate=0.05,
colsample_bytree=0.5, subsample=0.8)
best_xgb = print_best_params(xgb_reg, xgb_params)
from lightgbm import LGBMRegressor
lgbm_params = {'n_estimators':[1000]}
lgbm_reg = LGBMRegressor(n_estimators=1000, learning_rate=0.05, num_leaves=4,
subsample=0.6, colsample_bytree=0.4, reg_lambda=10, n_jobs=-1)
best_lgbm = print_best_params(lgbm_reg, lgbm_params)
def get_rmse_pred(preds):
for key in preds.keys():
pred_value = preds[key]
mse = mean_squared_error(y_test , pred_value)
rmse = np.sqrt(mse)
print('{0} 모델의 RMSE: {1}'.format(key, rmse))
ridge_reg = Ridge(alpha=8)
ridge_reg.fit(X_train, y_train)
lasso_reg = Lasso(alpha=0.001)
lasso_reg.fit(X_train, y_train)
ridge_pred = ridge_reg.predict(X_test)
lasso_pred = lasso_reg.predict(X_test)
pred = 0.4 * ridge_pred + 0.6 * lasso_pred
preds = {'최종 혼합': pred,
'Ridge': ridge_pred,
'Lasso': lasso_pred}
get_rmse_pred(preds)
xgb_reg = XGBRegressor(n_estimators=1000, learning_rate=0.05,
colsample_bytree=0.5, subsample=0.8)
lgbm_reg = LGBMRegressor(n_estimators=1000, learning_rate=0.05, num_leaves=4,
subsample=0.6, colsample_bytree=0.4, reg_lambda=10, n_jobs=-1)
xgb_reg.fit(X_train, y_train)
lgbm_reg.fit(X_train, y_train)
xgb_pred = xgb_reg.predict(X_test)
lgbm_pred = lgbm_reg.predict(X_test)
pred = 0.5 * xgb_pred + 0.5 * lgbm_pred
preds = {'최종 혼합': pred,
'XGBM': xgb_pred,
'LGBM': lgbm_pred}
get_rmse_pred(preds)from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds ):
kf = KFold(n_splits=n_folds, shuffle=False, random_state=0)
train_fold_pred = np.zeros((X_train_n.shape[0] ,1 ))
test_pred = np.zeros((X_test_n.shape[0],n_folds))
print(model.__class__.__name__ , ' model 시작 ')
for folder_counter , (train_index, valid_index) in enumerate(kf.split(X_train_n)):
print('\t 폴드 세트: ',folder_counter,' 시작 ')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
model.fit(X_tr , y_tr)
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1,1)
test_pred[:, folder_counter] = model.predict(X_test_n)
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1,1)
return train_fold_pred , test_pred_mean
X_train_n = X_train.values
X_test_n = X_test.values
y_train_n = y_train.values
ridge_train, ridge_test = get_stacking_base_datasets(ridge_reg, X_train_n, y_train_n, X_test_n, 5)
lasso_train, lasso_test = get_stacking_base_datasets(lasso_reg, X_train_n, y_train_n, X_test_n, 5)
xgb_train, xgb_test = get_stacking_base_datasets(xgb_reg, X_train_n, y_train_n, X_test_n, 5)
lgbm_train, lgbm_test = get_stacking_base_datasets(lgbm_reg, X_train_n, y_train_n, X_test_n, 5)
Stack_final_X_train = np.concatenate((ridge_train, lasso_train,
xgb_train, lgbm_train), axis=1)
Stack_final_X_test = np.concatenate((ridge_test, lasso_test,
xgb_test, lgbm_test), axis=1)
meta_model_lasso = Lasso(alpha=0.0005)
meta_model_lasso.fit(Stack_final_X_train, y_train)
final = meta_model_lasso.predict(Stack_final_X_test)
mse = mean_squared_error(y_test , final)
rmse = np.sqrt(mse)
print('스태킹 회귀 모델의 최종 RMSE 값은:', rmse)CH.5.11 _ 정리
선형회귀 = 실제값과 예측값의 차이인 오류를 최소로 줄일 수 있는 선형 함수를 찾아서, 선형 함수에 피처를 입력해 종속변수의 값을 예측하는 것
>> 과적합 문제를 유발할 수 있다.
이를 해결하기 위한 규제 = Regulariztion
L2를 활용한 릿지, L1을 활용한 라쏘, L1+L2 엘라스틱넷
선형 회귀를 분류에 적용한 모델 = 로지스틱 회귀
회귀 트리 = 분류 트리와 크게 다르지 않지만, 리프 노드에서 예측 결정값을 만드는 과정에 차이가 있다.
선형 회귀는 데이터 값의 분포도와 인코딩 방법에 큰 영향을 받는다
정규 분호와 같은 데이터 분포가 이뤄져 있으면 좋고, 타깃값의 분포가 skew되지 않고, 정규 분포 형태여야 예측 성능이 저하되지 않는다.
>> 조건 미충족시 로그 변환을 적용하면 좋다.
카테고리형 데이터가 있을 경우 원-핫 인코딩으로 변환해줘야 한다,
'Self-Taught > Machine Learning' 카테고리의 다른 글
| 머신러닝 완벽 가이드 _ CH.7 : 군집화 (0) | 2024.11.30 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 _CH.6 (0) | 2024.11.23 |
| 파이썬 머신러닝 완벽 가이드 _ CH.4.7~4.12 (1) | 2024.11.09 |
| 파이썬 머신러닝 완벽 가이드 _ CH.4.1~4.6 (1) | 2024.11.02 |
| 파이썬 머신 러닝 완벽 가이드 _ CH.3 (2) | 2024.10.12 |


