CH.8.6 _ 토픽 모델링
Topic Modeling : 숨어있는 중요 주제를 효과적으로 찾아낼 수 있는 모델을 만드는 과정
중심단어를 함축적으로 추출
Topic Modeling에 자주 사용되는 기법은 LSA(Latent Sematic Analysis)와 LDA(Latent Dirichlet Allocation)
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 모토사이클, 야구, 그래픽스, 윈도우, 중동, 기독교, 전자공학, 의학 8개의 주제를 추출하기 위한 cats
cats = ['rec.motorcycles', 'rec.sport.baseball', 'comp.graphics', 'comp.windows.x',
'talk.politics.mideast', 'soc.religion.christian', 'sci.electronics', 'sci.med']
# 위에서 cats 변수로 기재된 카테고리만 추출. fetch_20newsgroups()의 categories에 cats 입력
news_df = fetch_20newsgroups(subset = 'all', remove = ('headers', 'footers', 'quotes'),
categories = cats, random_state = 0)
# LDA는 Count기반의 벡터화만 사용
count_vect = CountVectorizer(max_df = 0.95, max_features = 1000, min_df = 2, stop_words = 'english',
ngram_range = (1, 2))
feat_vect = count_vect.fit_transform(news_df.data)
print('CountVectorizer Shape : ', feat_vect.shape)CountVectorizer Shape : (7862, 1000)
# n_components 이용하여 토픽 개수 조절
lda = LatentDirichletAllocation(n_components = 8, random_state = 0)
lda.fit(feat_vect)LatentDirichletAllocation(n_components=8, random_state=0)
LatentDirichletAllocation(데이터 세트) 수행 시 LatentDirichletAllocation 객체는 components_ 속성을 가짐
components_는 개별 토픽별로 각 word 피처가 얼마나 많이 그 토픽에 할당됐는지에 대한 수치(연관도)를 가지고 있음
높은 값일수록 해당 word 피처는 그 토픽의 중심 word가 됨
print(lda.components_.shape)
lda.components_(8, 1000)
array([[3.60992018e+01, 1.35626798e+02, 2.15751867e+01, ...,
3.02911688e+01, 8.66830093e+01, 6.79285199e+01],
[1.25199920e-01, 1.44401815e+01, 1.25045596e-01, ...,
1.81506995e+02, 1.25097844e-01, 9.39593286e+01],
[3.34762663e+02, 1.25176265e-01, 1.46743299e+02, ...,
1.25105772e-01, 3.63689741e+01, 1.25025218e-01],
...,
[3.60204965e+01, 2.08640688e+01, 4.29606813e+00, ...,
1.45056650e+01, 8.33854413e+00, 1.55690009e+01],
[1.25128711e-01, 1.25247756e-01, 1.25005143e-01, ...,
9.17278769e+01, 1.25177668e-01, 3.74575887e+01],
[5.49258690e+01, 4.47009532e+00, 9.88524814e+00, ...,
4.87048440e+01, 1.25034678e-01, 1.25074632e-01]])8개의 토픽별로 1000개의 word 피처가 해당토픽별로 연관도 값을 가지고 있음
즉, components_array의 0번째 row, 10번째 col에 있는 값은 Topic#0에 대해 피처 벡터화된 행렬에서 10번째 컬럼에
해당하는 피처가 Topic #0에 연관되는 수치값을 가지고 있음
# lda_model.components_ 값만으로는 각 토픽별 word 연관도를 보기 어려움
# display_topics()함수로 각 토픽별 연관도가 높은 순으로 Word를 나열
def display_topics(model, feature_names, no_top_words) :
for topic_index, topic in enumerate(model.components_) :
print('Topic #', topic_index)
# components_array 에서 가장 값이 큰 순으로 정렬했을 때, 그 값의 array 인덱스를 반환
topic_word_indexes = topic.argsort()[::-1]
top_indexes = topic_word_indexes[:no_top_words]
# top_indexes대상인 인덱스별로 feature_names에 해당하는 word feature 추출 후 join으로 concat
feature_concat = ' '.join([feature_names[i] for i in top_indexes])
print(feature_concat)
# CountVectorizer객체 내의 전체 word의 명칭을 get_feature_names()를 통해 추출
feature_names = count_vect.get_feature_names() # 1000개의 word 명칭
# 토픽별 가장 연관도가 높은 word를 15개만 추출
display_topics(lda, feature_names, 15)Topic # 0
year 10 game medical health team 12 20 disease cancer 1993 games years patients good
Topic # 1
don just like know people said think time ve didn right going say ll way
Topic # 2
image file jpeg program gif images output format files color entry 00 use bit 03
Topic # 3
like know don think use does just good time book read information people used post
Topic # 4
armenian israel armenians jews turkish people israeli jewish government war dos dos turkey arab armenia 000
Topic # 5
edu com available graphics ftp data pub motif mail widget software mit information version sun
Topic # 6
god people jesus church believe christ does christian say think christians bible faith sin life
Topic # 7
use dos thanks windows using window does display help like problem server need know run
Topic0 : 명확하지 않고 일반적인 단어가 주를 이룸
Topic1 : 명확하게 컴퓨터 그래픽스 영역의 주제어 추출
Topic2 : 기독교에 관련된 주제어 추출
Topic3 : 의학에 관련된 주제어 추출
Topic4 : 윈도우 운영체제와 관련된 주제어 추출
Topic5 : 일반적인 단어로 주제어 추출
Topic6 : 중동 분쟁 등에 관련된 주제어 추출
Topic7 : 애매하지만 윈도우 운영체제 관련 주제어 일부 추출
CH.8.7 _ 문서 군집화 소개와 실습
문서 군집화(Document Clustering)은 비슷한 텍스트 구성의 문서를 군집화 하는 것
텍스트 분류 기반의 문서 분류는 결정 카테고리 값을 가진 학습 데이터가 필요
그러나, 문서 군집화는 학습 데이터가 필요 없는 비지도학습 기반으로 동작
import pandas as pd
import glob, os
# 디렉토리 설정
path = r'C:\Users\82102\Desktop\sw\PythonMLGuide\OpinosisDataset1.0\OpinosisDataset1.0\topics'
# path로 지정한 디렉토리 밑에 모든 .data 파일의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일의 파일명은 filename_list로 취합
# 개별 파일의 파일 내용은 DataFrame 로딩 후 다시 string으로 변환해 opinion_text list로 취합
for file_ in all_files :
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_, index_col = None, header = 0, encoding = 'latin1')
# 절대 경로로 주어진 파일명을 가공, 맨 마지막 .data 확장자도 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
# 파일명 list와 파일 내용 list에 파일명과 파일 내용을 추가
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 list와 파일 내용 list 객체를 DataFrame으로 생성
document_df = pd.DataFrame({'filename' : filename_list, 'opinion_text' : opinion_text})
document_df.head()
# TF-IDF 피처 벡터화 수행하기 전, tokenizer 함수를 정의
from nltk.stem import WordNetLemmatizer
import nltk
import string
# ord는 문자의 유니코드 값을 반환, string.punctuation은 구두점
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens) :
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text) :
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
# TF-IDf 피처 벡터화 수행
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(tokenizer = LemNormalize, stop_words = 'english',
ngram_range = (1, 2), min_df = 0.05, max_df = 0.85)
# opinion_text 컬럼 값으로 피처 벡터화 수행
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
# K-평균 군집화 적용
from sklearn.cluster import KMeans
# 5개 집합으로 군집화 수행
km_cluster = KMeans(n_clusters = 5, max_iter = 10000, random_state = 0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
document_df['cluster_label'] = cluster_label
document_df.head()
# cluster_label이 0인 데이터들을 정렬
document_df[document_df['cluster_label'] == 0].sort_values(by = 'filename')
# Cluster #0은 호텔에 대한 리뷰로 군집화 되어 있음
# cluster_labe이 1인 데이터들을 정렬
document_df[document_df['cluster_label'] == 1].sort_values(by = 'filename')
# Cluster #1은 킨들, 아이팟, 넷북 등의 포터블 전자기기에 대한 리뷰로 군집화 되어 있음# cluster_label이 2인 데이터들을 정렬
document_df[document_df['cluster_label'] == 2].sort_values(by = 'filename')
# Cluster #2는 킨들, 아이팟, 넷북이 군집에 포함되어 있지만 주로 차량용 네비게이션 리뷰# cluster_label이 3인 데이터들을 정렬
document_df[document_df['cluster_label'] == 3].sort_values(by = 'filename')
# Cluster #3은 킨들 리뷰가 하나 섞여있긴 하지만, 대부분 호텔에 대한 리뷰로 군집화# cluster_label이 4인 데이터들을 정렬
document_df[document_df['cluster_label'] == 4].sort_values(by = 'filename')
# Cluster #4는 토요타와 혼다 등의 자동차에 대한 리뷰로 군집화위 경우, 군집 개수가 많게 설정되어 있어 세분화되어 군집화된 경향이 있음
중심개수를 5개에서 3개로 낮춰서 살펴본 결과
from sklearn.cluster import KMeans
# 3개의 집합으로 군집화
km_cluster = KMeans(n_clusters = 3, max_iter = 10000, random_state = 0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
# 소속 군집을 cluster_label 컬럼으로 할당
document_df['cluster_label'] = cluster_label
# Cluster 0
document_df[document_df['cluster_label'] == 0].sort_values(by = 'filename')
# Cluster #0은 포터블 전자기기에 대한 리뷰로 잘 군집화 되어있음# Cluster 1
document_df[document_df['cluster_label'] == 1].sort_values(by = 'filename')
# Cluster #1은 차에 대한 리뷰로 잘 군집화 되어있음# Cluster 2
document_df[document_df['cluster_label'] == 2].sort_values(by = 'filename')
# Cluster #2는 호텔에 대한 리뷰로 잘 군집화 되어있음KMeans는 각 군집을 구성하는 단어 피처가 군집의 중심(Centroid)을 기준으로 얼마나 가깝게 위치해 있는지 cluster_centers_라는 속성으로 제공 (ndarry 형태)
cluster_centers_는 배열 값으로 제공되며 행은 개별 군집, 열은 개별 피처
cluster_centers_[0, 1]은 0번 군집에서 두 번째 피처의 위치 값
cluster_centers shape : (3, 4611)
[[0.01005322 0. 0. ... 0.00706287 0. 0. ]
[0. 0.00092551 0. ... 0. 0. 0. ]
[0. 0.00099499 0.00174637 ... 0. 0.00183397 0.00144581]]
# cluster_centers_는 (3, 2409) 배열임. 군집이 3개, word 피처가 2409개로 구성되었음을 의미
# 0에서 1까지의 값을 가지며, 1에 가까울수록 중심과 가까운 값을 의미
# 1) cluster_centers_ 배열 내에서 가장 값이 큰 데이터의 위치 인덱스를 추출
# 2) 해당 인덱스를 이용해, 핵심 단어 이름과 그때의 상대 위치 추출
# 3) cluster_details라는 Dict 객체 변수에 기록하고 반환
# 위와 같은 동작을 수행하는 함수 get_cluster_details()의 구현
# 군집별 top n 핵심 단어, 그 단어의 중심 위치 상댓값, 대상 파일명을 반환함.
def get_cluster_details(cluster_model, cluster_data, feature_names, clusters_num, top_n_features = 10) :
cluster_details = {}
# cluster_centers array의 값이 큰 순으로 정렬된 인덱스 값을 반환
# 군집 중심점(centroid)별 할당된 word 피처들의 거리값이 큰 순으로 값을 구하기 위함.
centroid_feature_ordered_ind = cluster_model.cluster_centers_.argsort()[:, ::-1]
# 개별 군집별로 반복하면서 핵심 단어, 그 단어의 중심 위치 상댓값, 대상 파일명 입력
for cluster_num in range(clusters_num) :
# 개별 군집별 정보를 담을 데이터 초기화.
cluster_details[cluster_num] = {}
cluster_details[cluster_num]['cluster'] = cluster_num
# cluster_centers_.argsort()[:,::-1]로 구한 인덱스를 이용해 top n 피처 단어를 구함
top_feature_indexes = centroid_feature_ordered_ind[cluster_num, :top_n_features]
top_features = [feature_names[ind] for ind in top_feature_indexes]
# top_feature_indexes를 이용해 해당 피처 단어의 중심 위치 상댓값 구함.
top_feature_values = cluster_model.cluster_centers_[cluster_num,
top_feature_indexes].tolist()
# cluster_details 딕셔너리 객체에 개별 군집별 핵심단어와 중심위치 상대값, 해당 파일명 입력
cluster_details[cluster_num]['top_features'] = top_features
cluster_details[cluster_num]['top_features_value'] = top_feature_values
filenames = cluster_data[cluster_data['cluster_label'] == cluster_num]['filename']
filenames = filenames.values.tolist()
cluster_details[cluster_num]['filenames'] = filenames
return cluster_details
# 보기좋게 print 하기 위한 함수 구현
def print_cluster_details(cluster_details) :
for cluster_num, cluster_detail in cluster_details.items() :
print('###### Cluster {0}'.format(cluster_num))
print('Top features : ', cluster_detail['top_features'])
print('Reviews 파일명 : ', cluster_detail['filenames'][:7])
print('==============================================')
# 함수 사용
feature_names = tfidf_vect.get_feature_names()
cluster_details = get_cluster_details(cluster_model = km_cluster, cluster_data = document_df,
feature_names = feature_names, clusters_num = 3, top_n_features = 10)
print_cluster_details(cluster_details)
###### Cluster 0
Top features : ['screen', 'battery', 'keyboard', 'battery life', 'life', 'kindle', 'direction', 'video', 'size', 'voice']
Reviews 파일명 : ['accuracy_garmin_nuvi_255W_gps', 'battery-life_amazon_kindle', 'battery-life_ipod_nano_8gb', 'battery-life_netbook_1005ha', 'buttons_amazon_kindle', 'directions_garmin_nuvi_255W_gps', 'display_garmin_nuvi_255W_gps']
==============================================
###### Cluster 1
Top features : ['interior', 'seat', 'mileage', 'comfortable', 'gas', 'gas mileage', 'transmission', 'car', 'performance', 'quality']
Reviews 파일명 : ['comfort_honda_accord_2008', 'comfort_toyota_camry_2007', 'gas_mileage_toyota_camry_2007', 'interior_honda_accord_2008', 'interior_toyota_camry_2007', 'mileage_honda_accord_2008', 'performance_honda_accord_2008']
==============================================
###### Cluster 2
Top features : ['room', 'hotel', 'service', 'staff', 'food', 'location', 'bathroom', 'clean', 'price', 'parking']
Reviews 파일명 : ['bathroom_bestwestern_hotel_sfo', 'food_holiday_inn_london', 'food_swissotel_chicago', 'free_bestwestern_hotel_sfo', 'location_bestwestern_hotel_sfo', 'location_holiday_inn_london', 'parking_bestwestern_hotel_sfo']
==============================================
CH.8.8 _ 문서 유사도
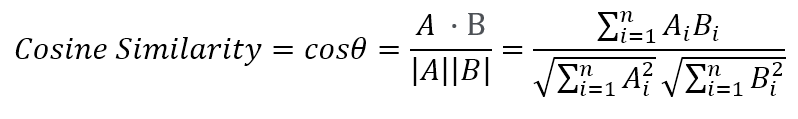
문서를 피처벡터화 하면, 차원이 매우 많은 희소 행렬이 되기 쉽다.
이때 문서와 문서 벡터간의 크기에 기반한 유사도 지표(유클리드 거리)는 정확도가 떨어지기 쉽다.
또한, 문서가 매우 긴 경우 단어의 빈도수도 더 많을 것이기에 이러한 빈도수 기반의 유사도 비교는 공정하지 않다.
예를 들어, A 문서에서 '머신러닝'이라는 단어가 5번 언급되고 B 문서에서 '머신러닝'이라는 단어가 3번 언급되었다고 할 때
A 문서가 '머신러닝'에 더 밀접하게 관련된 문서라고 판단하면 안된다.
# 두개의 넘파이 배열에 대한 코사인 유사도를 구하는 cos_similarity()함수 작성
import numpy as np
def cos_similarity(v1, v2) :
dot_product = np.dot(v1, v2)
l2_norm = (np.sqrt(sum(np.square(v1)))*np.sqrt(sum(np.square(v2))))
similarity = dot_product / l2_norm
return similarity
# doc_list로 정의된 3개의 간단한 문서의 유사도 비교하기
# TF-IDF로 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
doc_list = ['if you take the blue pill, the story ends',
'if you take the red pill, you stay in Wonderland',
'if you take the red pill, I show you how deep the rabbit hold goes']
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list)
print(feature_vect_simple.shape)(3, 18)
# 반환된 행렬은 희소 행렬.
# 밀집 행렬로 변환한 뒤 유사도 측정
# TfidfVectorizer로 transform()한 결과는 희소 행렬이므로 밀집 행렬로 변환.
feature_vect_dense = feature_vect_simple.todense()
# 첫 번째 문장과 두 번째 문장의 피처 벡터 추출
vect1 = np.array(feature_vect_dense[0]).reshape(-1, )
vect2 = np.array(feature_vect_dense[1]).reshape(-1, )
# 첫 번째 문장과 두 번째 문장의 피처 벡터로 두 개 문장의 코사인 유사도 추출
similarity_simple = cos_similarity(vect1, vect2)
print('문장 1, 문장 2 Cosine 유사도 : {0:.3f}'.format(similarity_simple))
# 첫 번째 문장과 세 번째 문장, 두 번째 문장과 세 번째 문장의 유사도 측정
vect3 = np.array(feature_vect_dense[2]).reshape(-1, )
similarity_simple = cos_similarity(vect1, vect3)
print('문장 1, 문장 3 Cosine 유사도 : {0:.3f}'.format(similarity_simple))
similarity_simple = cos_similarity(vect2, vect3)
print('문장 2, 문장 3 Cosine 유사도 : {0:.3f}'.format(similarity_simple))문장 1, 문장 2 Cosine 유사도 : 0.402
문장 1, 문장 3 Cosine 유사도 : 0.404
문장 2, 문장 3 Cosine 유사도 : 0.456
# 사이킷런의 cosine_similarity() API는 코사인 유사도를 지원
# 첫 번째 파라미터는 비교의 기준이 되는 문서의 피처 행렬
# 두 번째 파라미터는 비교되는 문서의 피처 행렬
# cosine_similarity()는 희소 행렬, 밀집 행렬 모두 가능하며 행렬 또는 배열 모두 가능.
from sklearn.metrics.pairwise import cosine_similarity
similarity_simple_pair = cosine_similarity(feature_vect_simple[0], feature_vect_simple)
print(similarity_simple_pair)[[1. 0.40207758 0.40425045]]
# 첫 번째 유사도 값인 1은 첫 번째 문서 자신에 대한 유사도
# 두 번째 유사도 값인 0.402는 첫 번째 문서와 두 번째 문서 간 유사도
# 세 번째 유사도 값인 0.404는 첫 번째 문서와 세 번째 문서 간 유사도similarity_simple_pair = cosine_similarity(feature_vect_simple[0], feature_vect_simple[1:])
print(similarity_simple_pair)
[[0.40207758 0.40425045]]
# 쌍으로(pair) 코사인 유사도 값 제공 가능
similarity_simple_pair = cosine_similarity(feature_vect_simple, feature_vect_simple)
print(similarity_simple_pair)
[[1. 0.40207758 0.40425045]
[0.40207758 1. 0.45647296]
[0.40425045 0.45647296 1. ]]
# Opinion Review 데이터 세트를 이용한 문서 유사도 측정
import pandas as pd
import glob, os
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
# 디렉토리 설정
path = r'C:\Users\rud92912\download\PythonMLGuide\OpinosisDataset1.0\OpinosisDataset1.0\topics'
# path로 지정한 디렉토리 밑에 모든 .data 파일의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일의 파일명은 filename_list로 취합
# 개별 파일의 파일 내용은 DataFrame 로딩 후 다시 string으로 변환해 opinion_text list로 취합
for file_ in all_files :
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_, index_col = None, header = 0, encoding = 'latin1')
# 절대 경로로 주어진 파일명을 가공, 맨 마지막 .data 확장자도 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
# 파일명 list와 파일 내용 list에 파일명과 파일 내용을 추가
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 list와 파일 내용 list 객체를 DataFrame으로 생성
document_df = pd.DataFrame({'filename' : filename_list, 'opinion_text' : opinion_text})# TF-IDF 피처 벡터화 수행하기 전, tokenizer 함수를 정의
from nltk.stem import WordNetLemmatizer
import nltk
import string
# ord는 문자의 유니코드 값을 반환, string.punctuation은 구두점
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens) :
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text) :
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
tfidf_vect = TfidfVectorizer(tokenizer = LemNormalize, stop_words = 'english',
ngram_range = (1, 2), min_df = 0.05, max_df = 0.85)
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
C:\Users\rud92912\anaconda3\lib\site-packages\sklearn\feature_extraction\text.py:388: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['ha', 'le', 'u', 'wa'] not in stop_words.
warnings.warn('Your stop_words may be inconsistent with 'km_cluster = KMeans(n_clusters = 3, max_iter = 10000, random_state = 0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
document_df['cluster_label'] = cluster_label
# 호텔을 주제로 군집화된 데이터 먼저 추출
# 이후, 이 데이터에 해당하는 TFidfVectorizer의 데이터를 추출
from sklearn.metrics.pairwise import cosine_similarity
# cluster_label = 2인 데이터는 호텔로 군집화된 데이터임. DataFrame에서 해당 인덱스 추출
hotel_indexes = document_df[document_df['cluster_label'] == 2].index
print('호텔로 군집화 된 문서들의 DataFrame Index : ', hotel_indexes)
# 호텔로 군집화된 데이터 중 첫 번째 문서를 추출해 파일명 표시
comparison_docname = document_df.iloc[hotel_indexes[0]]['filename']
print('##### 비교 기준 문서명', comparison_docname, '와 타 문서 유사도 #####')
'''
document_df에서 추출한 Index 객체를 feature_vect로 입력해 호텔 군집화된 feature_vect 추출
이를 이용해 호텔로 군집화된 문서 중 첫 번째 문서와 다른 문서간의 코사인 유사도 측정
'''
similarity_pair = cosine_similarity(feature_vect[hotel_indexes[0]], feature_vect[hotel_indexes])
print(similarity_pair)
호텔로 군집화 된 문서들의 DataFrame Index : Int64Index([1, 13, 14, 15, 20, 21, 24, 28, 30, 31, 32, 38, 39, 40, 45, 46], dtype='int64')
##### 비교 기준 문서명 bathroom_bestwestern_hotel_sfo 와 타 문서 유사도 #####
[[1. 0.0430688 0.05221059 0.06189595 0.05846178 0.06193118
0.03638665 0.11742762 0.38038865 0.32619948 0.51442299 0.11282857
0.13989623 0.1386783 0.09518068 0.07049362]]
# 첫 번쨰 문서와 다른 문서 간에 유사도가 높은 순으로 정렬하고 시각화
# cosine_similarity()는 쌍 형태의 ndarray를 반환하므로 판닥스 인덱스로 이용하기 위해
# reshape(-1)로 차원 변경
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 첫 번째 문서와 타 문서 간 유사도가 큰 순으로 정렬한 인덱스를 추출하되 자기 자신은 제외
sorted_index = similarity_pair.argsort()[:, ::-1]
sorted_index = sorted_index[:, 1:]
# 유사도가 큰 순으로 hotel_indexes를 추출해 재정렬
hotel_sorted_indexes = hotel_indexes[sorted_index.reshape(-1)]
# 유사도가 큰 순으로 유사도 값을 재정렬하되 자기 자신은 제외
hotel_1_sim_value = np.sort(similarity_pair.reshape(-1))[::-1]
hotel_1_sim_value = hotel_1_sim_value[1:]
# 유사도가 큰 순으로 정렬된 인덱스와 유사도 값을 이용해 파일명과 유사도 값을 막대 그래프로 시각화
hotel_1_sim_df = pd.DataFrame()
hotel_1_sim_df['filename'] = document_df.iloc[hotel_sorted_indexes]['filename']
hotel_1_sim_df['similarity'] = hotel_1_sim_value
sns.barplot(x = 'similarity', y = 'filename', data = hotel_1_sim_df)
plt.title(comparison_docname)
Text(0.5, 1.0, 'bathroom_bestwestern_hotel_sfo')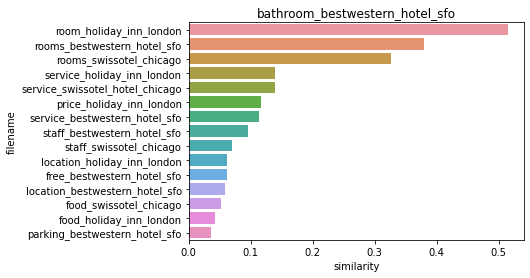
CH.8.9 _ 한글 텍스트 처리
한글 NLP가 어려운 이유
1) 띄어쓰기를 틀리는 경우가 자주 발생
2) 다양한 형태의 조사 존재
형태소 : 단어로서 의미를 가지는 최소 단위
형태소 분석 : 말뭉치를 형태소 어근 단위로 쪼개고, 각 형태소에 품사태깅을 부착하는 작업
import pandas as pd
# 데이터 출처 : https://github.com/e9t/nsmc
# 사용할 txt파일은 탭(\t)으로 컬럼이 구분되므로 sep를 '\t'로 설정
train_df = pd.read_csv('C:/Users/rud92912/download/PythonMLGuide/MovieReviewSA/ratings_train.txt', sep = '\t')
train_df.head()train_df['label'].value_counts()
train_df['document'].isnull().sum()
# document 컬럼에 Null이 존재하므로 이를 공백으로 변환
# 문자가 아닌 숫자의 경우 단어적 의미가 부족하므로 파이썬의 정규 표현인 모듈인
# re를 이용해 공백으로 변환
import re
train_df = train_df.fillna(' ')
# 정규 표현식을 이용해 숫자를 공백으로 변경(정규 표현식으로 \d는 숫자를 의미)
train_df['document'] = train_df['document'].apply(lambda x : re.sub(r"\d+", " ", x))
# 테스트 데이터 세트를 로딩하고 동일하게 Null 및 숫자를 공백으로 변환
test_df = pd.read_csv('C:/Users/82102/Desktop/sw/PythonMLGuide/MovieReviewSA/ratings_test.txt', sep = '\t')
test_df = test_df.fillna(' ')
test_df['document'] = test_df['document'].apply(lambda x : re.sub(r"\d+", " ", x))
# id 컬럼 상제 수행
train_df.drop('id', axis = 1, inplace = True)
test_df.drop('id', axis = 1, inplace = True)
# TF-IDF 방식으로 벡터화 진행, 형태소 단어로 토큰화 필요
# 한글 형태소 엔진은 SNS 분석에 적합한 Twitter 클래스 이용
# Twitter 객체의 morphs()메소드를 이용하면
# 문장(입력) -> 형태소 단위로 토큰화한 리스트(출력)
from konlpy.tag import Twitter
twitter = Twitter()
def tw_tokenizer(text) :
# 입력 인자로 들어온 텍스트를 형태소 단어로 토큰화해 리스트 형태로 반환
tokens_ko = twitter.morphs(text)
return tokens_ko
C:\Users\82102\anaconda3\lib\site-packages\konlpy\tag\_okt.py:17: UserWarning: "Twitter" has changed to "Okt" since KoNLPy v0.4.5.
warn('"Twitter" has changed to "Okt" since KoNLPy v0.4.5.')
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Twitter 객체의 morphs() 객체를 이용한 tokenizer를 사용. ngram-range는 (1, 2)
tfidf_vect = TfidfVectorizer(tokenizer = tw_tokenizer, ngram_range = (1, 2), min_df = 3, max_df = 0.9)
tfidf_vect.fit(train_df['document'])
tfidf_matrix_train = tfidf_vect.transform(train_df['document'])
# 로지스틱 회귀를 이용해 감성 분석 분류 수행
lg_clf = LogisticRegression(random_state = 0)
# 파라미터 C 최적화를 위해 GridSearchCV를 이용
params = {'C' : [1, 3.5, 4.5, 5.5, 10]}
grid_cv = GridSearchCV(lg_clf, param_grid = params, cv = 3,
scoring = 'accuracy', verbose = 1)
grid_cv.fit(tfidf_matrix_train, train_df['label'])
print(grid_cv.best_params_, round(grid_cv.best_score_, 4))
Fitting 3 folds for each of 5 candidates, totalling 15 fits
C:\Users\rud92912\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
C:\Users\82102\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result({'C': 3.5} 0.8592
C:\Users\rud92912\anaconda3\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(from sklearn.metrics import accuracy_score
# 학습 데이터를 적용한 TfidfVectorizer를 이용해 테스트 데이터를 TF-IDF 값으로 피처 변환함
tfidf_matrix_test = tfidf_vect.transform(test_df['document'])
# Classfier는 GridSearchCV에서 최적 파라미터로 학습된 classifier를 그대로 이용
best_estimator = grid_cv.best_estimator_
preds = best_estimator.predict(tfidf_matrix_test)
print('Logistic Regression 정확도 : ', accuracy_score(test_df['label'], preds))
Logistic Regression 정확도 : 0.86188
CH.8.10 _ 텍스트 분석 실습
#데이터 전처리
from sklearn.linear_model import Ridge , LogisticRegression
from sklearn.model_selection import train_test_split , cross_val_score
from sklearn.feature_extraction.text import CountVectorizer , TfidfVectorizer
import pandas as pd
mercari_df= pd.read_csv('mercari_train.tsv',sep='\t')
print(mercari_df.shape)
mercari_df.head(3)
print(mercari_df.info())
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
y_train_df = mercari_df['price']
plt.figure(figsize=(6,4))
sns.distplot(y_train_df,kde=False)
import numpy as np
y_train_df = np.log1p(y_train_df)
sns.distplot(y_train_df,kde=False)
mercari_df['price'] = np.log1p(mercari_df['price'])
mercari_df['price'].head(3)
print('Shipping 값 유형:\n',mercari_df['shipping'].value_counts())
print('item_condition_id 값 유형:\n',mercari_df['item_condition_id'].value_counts())
boolean_cond= mercari_df['item_description']=='No description yet'
mercari_df[boolean_cond]['item_description'].count()
# apply lambda에서 호출되는 대,중,소 분할 함수 생성, 대,중,소 값을 리스트 반환
def split_cat(category_name):
try:
return category_name.split('/')
except:
return ['Other_Null' , 'Other_Null' , 'Other_Null']
# 위의 split_cat( )을 apply lambda에서 호출하여 대,중,소 컬럼을 mercari_df에 생성.
mercari_df['cat_dae'], mercari_df['cat_jung'], mercari_df['cat_so'] = \
zip(*mercari_df['category_name'].apply(lambda x : split_cat(x)))
# 대분류만 값의 유형과 건수를 살펴보고, 중분류, 소분류는 값의 유형이 많으므로 분류 갯수만 추출
print('대분류 유형 :\n', mercari_df['cat_dae'].value_counts())
print('중분류 갯수 :', mercari_df['cat_jung'].nunique())
print('소분류 갯수 :', mercari_df['cat_so'].nunique())
mercari_df['brand_name'] = mercari_df['brand_name'].fillna(value='Other_Null')
mercari_df['category_name'] = mercari_df['category_name'].fillna(value='Other_Null')
mercari_df['item_description'] = mercari_df['item_description'].fillna(value='Other_Null')
# 각 컬럼별로 Null값 건수 확인. 모두 0가 나와야 함
mercari_df.isnull().sum()
#피처 인코딩 & 피처 벡터화
print('brand name 의 유형 건수 :', mercari_df['brand_name'].nunique())
print('brand name sample 5건 : \n', mercari_df['brand_name'].value_counts()[:5])
print('name 의 종류 갯수 :', mercari_df['name'].nunique())
print('name sample 7건 : \n', mercari_df['name'][:7])
pd.set_option('max_colwidth', 200)
# item_description의 평균 문자열 개수
print('item_description 평균 문자열 개수:',mercari_df['item_description'].str.len().mean())
mercari_df['item_description'][:2]
# name 속성에 대한 feature vectorization 변환
cnt_vec = CountVectorizer()
X_name = cnt_vec.fit_transform(mercari_df.name)
# item_description 에 대한 feature vectorization 변환
tfidf_descp = TfidfVectorizer(max_features = 50000, ngram_range= (1,3) , stop_words='english')
X_descp = tfidf_descp.fit_transform(mercari_df['item_description'])
print('name vectorization shape:',X_name.shape)
print('item_description vectorization shape:',X_descp.shape)
from sklearn.preprocessing import LabelBinarizer
# brand_name, item_condition_id, shipping 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_brand_name= LabelBinarizer(sparse_output=True)
X_brand = lb_brand_name.fit_transform(mercari_df['brand_name'])
lb_item_cond_id = LabelBinarizer(sparse_output=True)
X_item_cond_id = lb_item_cond_id.fit_transform(mercari_df['item_condition_id'])
lb_shipping= LabelBinarizer(sparse_output=True)
X_shipping = lb_shipping.fit_transform(mercari_df['shipping'])
# cat_dae, cat_jung, cat_so 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_cat_dae = LabelBinarizer(sparse_output=True)
X_cat_dae= lb_cat_dae.fit_transform(mercari_df['cat_dae'])
lb_cat_jung = LabelBinarizer(sparse_output=True)
X_cat_jung = lb_cat_jung.fit_transform(mercari_df['cat_jung'])
lb_cat_so = LabelBinarizer(sparse_output=True)
X_cat_so = lb_cat_so.fit_transform(mercari_df['cat_so'])
print(type(X_brand), type(X_item_cond_id), type(X_shipping))
print('X_brand_shape:{0}, X_item_cond_id shape:{1}'.format(X_brand.shape, X_item_cond_id.shape))
print('X_shipping shape:{0}, X_cat_dae shape:{1}'.format(X_shipping.shape, X_cat_dae.shape))
print('X_cat_jung shape:{0}, X_cat_so shape:{1}'.format(X_cat_jung.shape, X_cat_so.shape))
from scipy.sparse import hstack
import gc
sparse_matrix_list = (X_name, X_descp, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
# 사이파이 sparse 모듈의 hstack 함수를 이용하여 앞에서 인코딩과 Vectorization을 수행한 데이터 셋을 모두 결합.
X_features_sparse= hstack(sparse_matrix_list).tocsr()
print(type(X_features_sparse), X_features_sparse.shape)
# 데이터 셋이 메모리를 많이 차지하므로 사용 용도가 끝났으면 바로 메모리에서 삭제.
del X_features_sparse
gc.collect()
#릿지 회귀 모델 구축 및 평가
def rmsle(y , y_pred):
# underflow, overflow를 막기 위해 log가 아닌 log1p로 rmsle 계산
return np.sqrt(np.mean(np.power(np.log1p(y) - np.log1p(y_pred), 2)))
def evaluate_org_price(y_test , preds):
# 원본 데이터는 log1p로 변환되었으므로 exmpm1으로 원복 필요.
preds_exmpm = np.expm1(preds)
y_test_exmpm = np.expm1(y_test)
# rmsle로 RMSLE 값 추출
rmsle_result = rmsle(y_test_exmpm, preds_exmpm)
return rmsle_result
import gc
from scipy.sparse import hstack
def model_train_predict(model,matrix_list):
# scipy.sparse 모듈의 hstack 을 이용하여 sparse matrix 결합
X= hstack(matrix_list).tocsr()
X_train, X_test, y_train, y_test=train_test_split(X, mercari_df['price'],
test_size=0.2, random_state=156)
# 모델 학습 및 예측
model.fit(X_train , y_train)
preds = model.predict(X_test)
del X , X_train , X_test , y_train
gc.collect()
return preds , y_test
linear_model = Ridge(solver = "lsqr", fit_intercept=False)
sparse_matrix_list = (X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds , y_test = model_train_predict(model=linear_model ,matrix_list=sparse_matrix_list)
print('Item Description을 제외했을 때 rmsle 값:', evaluate_org_price(y_test , linear_preds))
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds , y_test = model_train_predict(model=linear_model , matrix_list=sparse_matrix_list)
print('Item Description을 포함한 rmsle 값:', evaluate_org_price(y_test ,linear_preds))
#LightGBM 회귀 모델 구축과 앙상블을 이용한 최종 예측 평가
from lightgbm import LGBMRegressor
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
lgbm_model = LGBMRegressor(n_estimators=200, learning_rate=0.5, num_leaves=125, random_state=156)
lgbm_preds , y_test = model_train_predict(model = lgbm_model , matrix_list=sparse_matrix_list)
print('LightGBM rmsle 값:', evaluate_org_price(y_test , lgbm_preds))LightGBM rmsle 값: 0.4558577120744113
preds = lgbm_preds * 0.45 + linear_preds * 0.55
print('LightGBM과 Ridge를 ensemble한 최종 rmsle 값:', evaluate_org_price(y_test , preds))
LightGBM과 Ridge를 ensemble한 최종 rmsle 값: 0.4501738147377442CH.8.11 _ 정리
머신러닝 기반의 텍스트 분석 프로세스
1. 사전 정제 작업 등의 텍스트 정규화 작업 수행
2. 이들 단어들을 픽처 벡터화 변환
3. 생성된 피처 벡터 데이터 세트에 머신러닝 모델을 학습, 예측, 평가
텍스트 정규화 작업은 텍스트 클렌징 및 대소문자 변경, 단어 토큰화, 의미 없는 단어 필터링, 어근 추출 등 피처 벡터화를 진행하기 이전에 수행하는 다양한 사전 작업
텍스트 분류에서는 문서들을 피처 벡터화한 후 로지스틱 회귀를 적용해 문서를 지도학습 방식으로 예측 분류 진행
감성 분석에서는 지도학습 기반 긍정/부정 이진 분류 방식과 SentiWordNet, VADER와 같은 감성 사전 Lexicon을 이용한 방식 두 가지를 살펴봄
LDA를 이용해 공통적으로 토픽을 추출하는 토픽 모델링 진행텍스트 군집화는 K-평균 군집화 기법을 이용해 비슷한 문서끼리 군집화했으며 텍스트 유사도 측정에서는 코사인 유사도를 이용해 문서들끼리 얼마나 비슷한지 측정
KoNLPy 패키지를 이용해 영화 리뷰에 긍정/부정 이진 분류 진행
'Self-Taught > Machine Learning' 카테고리의 다른 글
| 머신러닝 완벽 가이드 _ CH.7 : 군집화 (0) | 2024.11.30 |
|---|---|
| 파이썬 머신러닝 완벽 가이드 _CH.6 (0) | 2024.11.23 |
| 파이썬 머신러닝 완벽 가이드 _CH.5 (0) | 2024.11.16 |
| 파이썬 머신러닝 완벽 가이드 _ CH.4.7~4.12 (1) | 2024.11.09 |
| 파이썬 머신러닝 완벽 가이드 _ CH.4.1~4.6 (0) | 2024.11.02 |



